

As I explain in my IoT book Digitize or Die, the big change of the Internet of Things (IoT) is the fact that it provides ample new sources to capture and leverage previously unavailable data from connected things.
The current wave of connecting people with machines and machines to machines will unleash a flow of data that has never been experienced. Within in the meteoric rise of data volumes, the IoT is poised to play an even larger role than it already does.
In my book I write that the sum of all data created in the next few years will be at least ten times more than the total of all data generated up to this point, jumping to 44 zettabytes by 2020. More importantly, the proportion of sensor data grows much faster than the volume of data from all sources combined.
The origins of the data lake concept
The Internet of Things is one of the main drivers of rapidly growing data sets. Analyzing large data sets and extracting information from them is what Big Data Analytics is all about – and it’s here that data lakes, the topic of this post, come in.
You can analyze IoT data for many goals. When you need real-time analysis in critical applications, edge computing might prove to be important. The IoT and growing demands for real-time analytics haven’t just led to new computing paradigms whereby more data gets processed at the edge (the essence of edge computing), they also continue to change the ways we work with data and organize data management.
Sensor data (regardless of the ways you might already have used it for real-time purposes) can be stored it in its raw format along with other data to gain insights on a higher level for different reasons and use cases which you might not even know yet. In fact, when organizations discover the potential of the IoT and its related technologies they also tend to discover new use cases while experimenting and learning from initial deployments. In practice this often means that they need the ability to go back to this raw data: to ask new questions of it and of aggregated data.

Raw data from among others IoT sensors can be added to data lakes to apply machine learning and real-time analytics – source and credit
As I describe in an interview, entitled ‘Data Will Be the Next Oil‘, aggregating data so that it can be useful presents different questions and opportunities alike. In the post I give some examples of what can be achieved and point to the challenge of dark data. This is data that exists but isn’t used today, yet can be used tomorrow.
The changing data landscape that came with Big Data – and the potential to store, aggregate and analyze so many sources, streams, types and volumes of data – explains why data lakes were “invented”. In 2010, James Dixon, back then the CTO of company Pentaho, wrote a blog post in which he introduced the concept of a data lake.
Dixon understood that there are indeed some known questions to ask of data but that there also were many unknown questions that would arise in the future. And he was right. Dixon described a data lake as follows: “If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
For many data lakes seemed to be a great approach for the age of Big Data, essentially all data: from server logs, social media data and input from ample systems and document types to sensor data. Data lakes quickly achieved hype status but it didn’t take long before analysts found that data lake deployments failed for many reasons, ranging from the ways data lake architectures were set up and the capabilities offered by the main platform to build data lakes to the mindset of organizations that weren’t used to the Big Data analysis mindset yet.
The opportunities for organizations to leverage data from sensors to create value are huge, especially in combination with other data from various sources – and when applying artificial intelligence and machine learning to analyze large data sets.
The present and future of data lakes
Today this is changing. The data maturity of organizations is growing, there are evolutions in the capabilities of platforms to build data lakes and, although a large percentage of data lakes is still deployed on-premises, more companies opt for the inherent benefits of data lakes as a service (in the cloud).
One of the main benefits of a data lake is that it enables us to gather source data, unstructured, structured and semi-structured, from multiple sources to harness this data, without the need to know all the questions we’ll want to ask the data and the value we’ll be able to generate in the future.
So, a data lake is not a one-size-fits-all data management solution, it exists for specific reasons. Moreover, the environment to manage data has become more diverse than it used to be. A data lake has a place in this complex data management environment and machine learning needs to access raw data to find patterns between various data.
In my book I emphasize the importance of raw data in the Internet of Things. The rawer the data you collect in manufacturing, for example, the more you can build knowledge and deliver better values.
A data lake is a storage repository that can store large amounts of structured, semi-structured, and unstructured data.
As things get more and more connected, the need and value of information will exponentially grow, and historical and live streams of raw data will become more valuable over time as they enable the next digital milestones such as augmented reality and virtual reality, predictive analytics and the usage of artificial Intelligence and deep learning.
A data lake enables you to keep as much raw data as you can with the proper tagging so that you can go back to this raw data when the opportunity presents itself for new applications and to unleash the power of machine learning. And, as you can read here, data lakes are extremely relevant for event-based, streaming data, typically generated by sources such as web application logs and sensors in IoT devices.
Data lakes and data warehouses
Data lakes are often compared with data warehouses because they are differently used and structured for different types of data.
Another term you will encounter in the context of data management that is closer to data warehouses is a data mart. In practice, however, they are often used together, all having their place and different purposes.
Data warehouses exist since a very long time (before anyone talked about Big Data) and typically capture structured information. They are more used when the source data and outputs are known (i.e. pre-defined questions for pre-defined types of data) while data lakes, as explained, are fit to manage a large diversity of data types with data kept in its raw form for big data analytics and machine learning. Data lakes are also more scalable than data warehouses and enable to analyze data for new questions it needs to answer faster given the fact that it doesn’t need to be organized as much as data in a data warehouse as the image below illustrates.
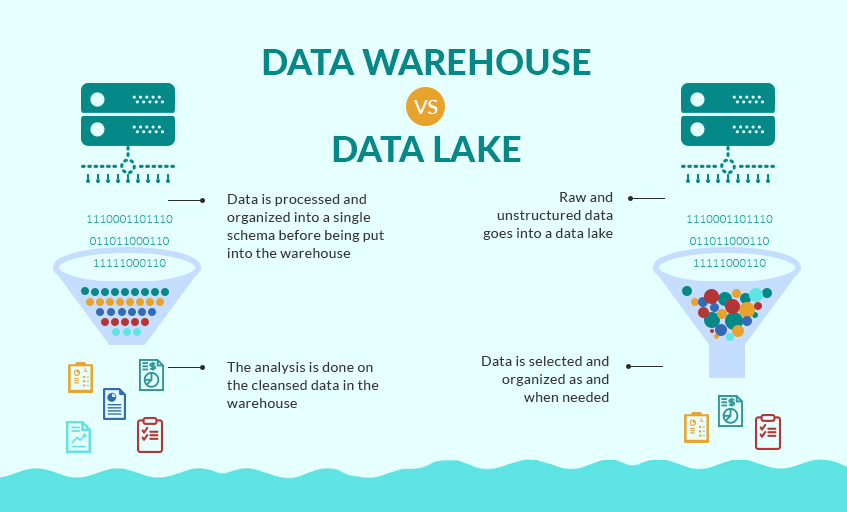
Data Lake vs Data Warehouse – source and credit
Top image credit: Cloud Technology Partners.